
Research Assistant
University of Birmingham, School of Computer Science

I earned my Ph.D. degree in the Intelligent Robotics Laboratory under the supervision of Dr. Hyung Jin Chang and Prof. Ales Leonardis, at the School of Computer Science, College of Engineering and Physical Sciences , University of Birmingham.
I completed my Master's thesis work in the Research Group on Visual Computation under the supervision of Prof. Zoltan Kato, at the Department of Image Processing and Computer Graphics, Institute of Informatics, Faculty of Science and Informatics, University of Szeged. I graduated as an Info-bionics Engineer M.Sc. from University of Szeged in the Faculty of Science and Informatics in January, 2018.
I received my Bachelor of Science degree in Molecular Bionics Engineering from University of Szeged in January, 2016. Between 2013-2016 I was working as a student researcher in the Biological Research Center of Szeged in the Biological Barriers Research Group under the supervision of Dr. Maria Deli, at the Institute of Biophysics.
Contact
E-mail: ku.ca.mahb.inmula@048hxn
Ph.D. in Computer Science
School of Computer Science, College of Engineering and Physical Sciences, University of Birmingham
Thesis topic: Human attention target estimation and application on images
M.Sc. in Info-bionics Engineering
Institute of Informatics, University of Szeged
Thesis title: Absolute pose estimation using 3D-2D line correspondences and vertical direction — Excellent with institutional award
B.Sc. in Molecular Bionics Engineering
Institute of Chemistry, University of Szeged
Thesis title: Measurement of electric surface charge on cultured brain endothelial cells — Excellent with national awards
University of Birmingham, School of Computer Science
University of Birmingham, School of Computer Science
Technical University Dresden, Chair of Computer Graphics and Visualisation
UMR 7039 CNRS and University of Lorraine, Research Center in Automatic Control of Nancy
University of Szeged, Research Group on Visual Computation
Biological Research Center of Szeged, Hungarian Academy of Sciences, Biological Barriers Research Group
Venue: Punta Sampieri, Ragusa, Scicli (Ragusa)
Venue: Artificial Intelligence and Information Analysis Lab, Aristotle University of Thessaloniki, Greece
Venue: Czech Technical University, Prague, Czech Republic
Venue: University of Szeged, Hungary
Venue: Eotvos Lorand University, Budapest, Hungary
Venue: University of Szeged, Hungary


Most computer vision applications, such as automatic image cropping and attention target estimation, aim to perform or solve a task as humans would. While recent works using Neural Networks showed promising results in numerous research areas, complex and subjective tasks are still challenging to solve by only deriving information from images and videos. Therefore to enhance the ability of the machine to localise a part of an image or to interpret complex social interactions between multiple people in the scene like humans would, explicit or implicit user input could be integrated into the algorithm. This thesis investigates the usefulness of explicit verbal and implicit non-verbal human social clues and their combination in frameworks designed for attention-based computer vision tasks. The proposed computational methods in this thesis aim to better understand the user's intention through different input modalities. Specifically, this work used natural language and its combination with eye-tracking user inputs for description-based image cropping and visual attention for joint attention target estimation.
This work studied how a natural language expression of the users could be directly used to automatically localise the described part of an image and output an aesthetically pleasing image crop. The proposed solution re-purposed existing deep learning models into a single optimisation framework to solve this complex, highly subjective problem. In addition to the explicit language expressions and a semi-direct social clue, the eye movements of the users were integrated into a novel multi-modal framework. Finally, motivated by the usefulness of the user's semi-direct attention input, a deep neural network was developed for estimating attention targets in images to detect and follow the joint attention target of the subjects within the scene.
The presented approaches have achieved state-of-the-art performances in quantitative and qualitative measures on different benchmark datasets in their respective research areas. Furthermore, the conducted studies confirmed that the users favoured the output of the proposed solutions. These findings prove that integrating explicit or implicit user input and their combination into computational methods can produce more human-like outputs.
Keywords: multi-modal framework, computer vision applications, description-based image cropping, eye-tracking, joint attention target estimation
I express my gratitude for the "School of Computer Science Studentship" funding that I received towards my PhD from the University of Birmingham's School of Computer Science. This research was supported by the Institute of Information and communications Technology Planning, and evaluation (IITP) grants funded by the Korean government (MSIT) (2021-0-00537, Visual common sense through self-supervised learning for restoration of invisible parts in images; 2021-0-00034, Clustering technologies of fragmented data for time-based data analysis). This work was partially supported by the Natural Sciences and Engineering Research Council of Canada (NSERC) Discovery Grant ``Deep Visual Geometry Machines'' (RGPIN-2018-03788) and by systems supplied by Compute Canada. I also acknowledge MoD/Dstl and EPSRC for providing the grant to support the UK academics involvement in a Department of Defense funded MURI project through EPSRC grant EP/N019415/1, and IITP grant funded by the Korean government (MSIT) (IITP-2020-0-01789, ITRC support program). We thank NVIDIA for sponsoring one GeForce Titan Xp GPU.
I worked as a Research Associate at Chair of Computer Graphics and Visualization, Technical University of Dresden, Germany under the supervision of Prof. Dr. Stefan Gumhold in the framework of the NeuroFusion project.
The research focuses on Computer Vision and Computer Graphics for Medical Imaging within the interdisciplinary research project "NeuroFusion". The objective of the research project lies in the development of a neurosurgical assistance system for medical personnel which visualizes the characteristic strengths of various imaging modalities in a single view. For this purpose, novel image registration and -fusion methods have to be developed so that a joint visualization of preoperative imaging, such as MRI and CT, as well as intraoperative imaging, such as 3D-ultrasound, stereo- and thermal imaging, can be achieved. Therefore, we aim to develop a generic mathematical framework for multimodal image registration and -fusion.

The research project focuses on estimating the location and orientation of a moving stereo rig using extracted feature correspondences (e.g. points, lines, regions). The algorithm makes use of other sensors mounted on the same platform (e.g. GPS, IMU), but the final pose estimate is obtained via computer vision techniques. In general, pose estimation has 6 degree of freedom, but in our project we will develop algorithms for important special cases like pose estimation with known vertical direction, where the number of free parameters can be reduced to 4. The estimated camera pose can be used to implement viusal odometry.
Pose estimation is a fundamental building block of various vision applications, e.g. visual odometry, image based localization and navigation, fusion, and augmented reality. Herein, we are interested in absolute pose estimation, which consists of determining the position and orientation of a camera with respect to a 3D world coordinate frame. We propose a novel solution to the gPnL problem with known vertical direction. The vertical direction is typically obtained from an IMU (Inertial Measurement Unit). The only assumption about our generalized camera is that projection rays of a 3D line fall into coplanar subsets yielding a pencil of projection planes. Important special cases of such a camera include stereo and multiview perspective camera systems, perspective camera moving along a trajectory, as well as other non-perspective cameras with central omnidirectional or orthographic projection.
| Video 1. Presentation of the extracted lines which we used for our algorithm as a least squares solver to estimate the position of the camera system. The corresponding 3D lines are shown with the same color as the camera. |
For the quantitative evaluation of our generalized pose estimation algorithm with line correspondences, we generated various benchmark datasets of 3D-2D line pairs. Each dataset has 1000 samples. Our method can be used as a least square solver as well as a minimal solver without reformulation. For the minimal case we only need 3 line pairs. The method was quantitatively evaluated on this large synthetic dataset as well as on a real dataset, which confirms its state of the art performance both in terms of quality and computational efficiency.
| Video 2. Lidar laser scan for testing our least squares solver pose estimation algorithm with a 3-perspective-1-omnidirectional multi-view camera system. On the Lidar scan red dots are the estimated positions and green dots are the real location of the markers in metric 3D space. |
| Video 3. Lidar laser scan for testing our minimal solver pose estimation algorithm solver with a 3-perspective camera system. On the Lidar scan, red dots are the estimated positions of our minimal solver, blue dots are the estimated positions of NP3L [G.H.Lee, ECCV 2016], and green dots are the real location of the markers in the 3D metric space. |
This work is partially supported by: the "Integrated program for training new generation of scientists in the fields of computer science", no EFOP-3.6.3-VEKOP-16-2017-0002; NKFI-6 fund through project K120366; the Agence Universitaire de la Francophonie (AUF) and the Romanian Institute for Atomic Physics (IFA), through the AUF-RO project NETASSIST; the Research & Development Operational Programme for the project "Modernization and Improvement of Technical Infrastructure for Research and Development of J. Selye University in the Fields of Nanotechnology and Intelligent Space", ITMS 26210120042, co-funded by the European Regional Development Fund.
She visited as a student researcher at Research Center in Automatic Control of Nancy, UMR 7039 CNRS and University of Lorraine in the framework of the NETASSIST project funded by AUF. This project develops methods for the networked control and sensing for a team of unmanned, assistive aerial vehicles that follows a group of vulnerable persons. On the control side, we consider multi-agent and consensus techniques, while on the vision side the focus is egomotion estimation of the UAVs and cooperative tracking of persons with filtering techniques. NETASSIST is an international cooperation project involving the Technical University of Cluj-Napoca in Romania, the University of Szeged in Hungary, and the University of Lorraine at Nancy, France.
The goal of this visit was to develop a drone control application based on sensor and visual information. For this we planned to process the stream of position and attitude measurements given by the vision algorithms, which she developed in her home institute, on a video taken from the drone, using a state estimator / filter and the dynamics of the drone. For the above-mentioned vision algorithm, she needed to work with 2D images and 3D dataset provided by OptiTrack and solve the question of feature extraction and matching in a video sequence for visual odometry application.
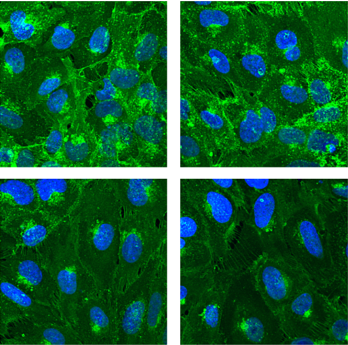
Glycocalyx which can be found in the surface of the endothalial cells is the part of the blood-brain barrier's protection system and it has effect on the limitation of the material access. Research on the composition, rule and the change of the glycocalyx in illnesses recently became a significant research topic. However, we do not have data about the intestinal epithelial cell and particularly in the cerebral microvessels' glycocalyx volume and a change in cell surface charge of direct measurements which have been performed. Our aim was therefore a direct measurement of surface charge of cultured brain endothelial cells and to examine how the surface charge and endothelial cell layers permeability change after the enzymatic digestion of the glycocalyx.
In our experiments D3 immortalized human brain endothelial cell line and primary rat brain endothelial cell cultures were employed. The amount of the glycocalyx was reduced by neuraminidase, trypsin and hyaluronidase enzymes which changes were validated using specific fluorescent labeled wheatgerm N-acetyl-D-glucosamine and sialic acid binding lectin. We took images from the binding of labeled lectin with confocal microscopy which fluorescence intensity was evaluated by Image J software. Cerebral endothelial cell surface charge was measured by the Malvern Zetasizer Nano ZS instrument. The brain endothelial cell lines were cultured into inserts to test their barrier function. We transferred dextran and Evans blue-albumin complex as a fluorescent reporter molecule to examine the cultures.
We successfully measured the surface charge of brain endothelial cells, and both cell types had strongly negative zeta potential which correlates to the literature. All three enzymes digested the glycocalyx and reduced the binding of the lectin. At the same time, the absolute value of the surface negative charge significantly reduced in both cell types. However, hyaluronidase and neuraminidase enzyme treatments did not affect the passage of the markers. The permeability increased only in the case of the trypsin digestion, although this enzyme cleavages the extracellular connections thus opens the paracellular transport route, which was visible in the morphological images.
We were the first one measuring and discribing the surface negative charge changes after the enzymatic digestion of the glycocalyx in human and rat brain endothelial cells. We found that the significant part of the surface charge origin from the glycocalyx in these cells, as after the enzymatic digestion the zeta potential of the cells became more positive. Reduction of the volume of the glycocalyx however did not affect the passage of the markers with neutral charge. In our future plans, we consider to use different materials with positive and negative charge for the surface modification of the glycocalyx, as well as to use other indicators with different charges in the permeability experiments.
Most computer vision applications, such as automatic image cropping and attention target estimation, aim to perform or solve a task as humans would. While recent works using Neural Networks showed promising results in numerous research areas, complex and subjective tasks are still challenging to solve by only deriving information from images and videos. Therefore to enhance the ability of the machine to localise a part of an image or to interpret complex social interactions between multiple people in the scene like humans would, explicit or implicit user input could be integrated into the algorithm. This thesis investigates the usefulness of explicit verbal and implicit non-verbal human social clues and their combination in frameworks designed for attention-based computer vision tasks. The proposed computational methods in this thesis aim to better understand the user's intention through different input modalities. Specifically, this work used natural language and its combination with eye-tracking user inputs for description-based image cropping and visual attention for joint attention target estimation.
This work studied how a natural language expression of the users could be directly used to automatically localise the described part of an image and output an aesthetically pleasing image crop. The proposed solution re-purposed existing deep learning models into a single optimisation framework to solve this complex, highly subjective problem. In addition to the explicit language expressions and a semi-direct social clue, the eye movements of the users were integrated into a novel multi-modal framework. Finally, motivated by the usefulness of the user's semi-direct attention input, a deep neural network was developed for estimating attention targets in images to detect and follow the joint attention target of the subjects within the scene.
The presented approaches have achieved state-of-the-art performances in quantitative and qualitative measures on different benchmark datasets in their respective research areas. Furthermore, the conducted studies confirmed that the users favoured the output of the proposed solutions. These findings prove that integrating explicit or implicit user input and their combination into computational methods can produce more human-like outputs.
We propose a novel depth-aware joint attention target estimation framework that estimates the attention target in 3D space. Our goal is to mimic human's ability to understand where each person is looking in their proximity. In this work, we tackle the previously unexplored problem of utilising a depth prior along with a 3D joint FOV probability map to estimate the joint attention target of people in the scene. We leverage the insight that besides the 2D image content, strong gaze-related constraints exist in the depth order of the scene and different subject-specific attributes. Extensive experiments show that our method outperforms favourably against existing joint attention target estimation methods on the VideoCoAtt benchmark dataset. Despite the proposed framework being designed for joint attention target estimation, we show that it outperforms single attention target estimation methods on both the GazeFollow image and the VideoAttentionTarget video benchmark datasets.
We propose a novel gaze-initialized optimization framework to generate aesthetically pleasing image crops based on user description. We extended the existing description-based image cropping dataset by collecting user eye movements corresponding to the image captions. To best leverage the contextual information to initialize the optimization framework using the collected gaze data, this work proposes two gaze-based initialization strategies, Fixed Grid and Region Proposal. In addition, we propose the adaptive Mixed scaling method to find the optimal output despite the size of the generated initialization region and the described part of the image. We address the runtime limitation of the state-of-the-art method by implementing the Early termination strategy to reduce the number of iterations required to produce the output. Our experiments show that G-DAIC reduced the runtime by 92.11%, and the quantitative and qualitative experiments demonstrated that the proposed framework produces higher quality and more accurate image crops w.r.t. user intention.
Fast and accurate tracking of an object's motion is one of the key functionalities of a robotic system for achieving reliable interaction with the environment. This paper focuses on the instance-level six-dimensional (6D) pose tracking problem with a symmetric and textureless object under occlusion. We propose a Temporally Primed 6D pose tracking framework with Auto-Encoders (TP-AE) to tackle the pose tracking problem. The framework consists of a prediction step and a temporally primed pose estimation step. The prediction step aims to quickly and efficiently generate a guess on the object's real-time pose based on historical information about the target object's motion. Once the prior prediction is obtained, the temporally primed pose estimation step embeds the prior pose into the RGB-D input, and leverages auto-encoders to reconstruct the target object with higher quality under occlusion, thus improving the framework's performance. Extensive experiments show that the proposed 6D pose tracking method can accurately estimate the 6D pose of a symmetric and textureless object under occlusion, and significantly outperforms the state-of-the-art on T-LESS dataset while running in real-time at 26 FPS.
We propose a novel optimization framework that crops a given image based on user description and aesthetics. Unlike existing image cropping methods, where one typically trains a deep network to regress to crop parameters or cropping actions, we propose to directly optimize for the cropping parameters by repurposing pre-trained networks on image captioning and aesthetic tasks, without any fine-tuning, thereby avoiding training a separate network. Specifically, we search for the best crop parameters that minimize a combined loss of the initial objectives of these networks. To make the optimization stable, we propose three strategies: (i) multi-scale bilinear sampling, (ii) annealing the scale of the crop region, therefore effectively reducing the parameter space, (iii) aggregation of multiple optimization results. Through various quantitative and qualitative evaluations, we show that our framework can produce crops that are well-aligned to intended user descriptions and aesthetically pleasing.
Cell surface charge is an important element of the function of biological barriers, but no chip device has been described to measure cell surface charge properties of confluent barrier cell monolayers. The aim of this study was the design and fabrication of a dynamic lab-on-a-chip (LOC) device which is suitable to monitor transcellular electrical resistance, as well as streaming potential parallel to the surface of cell layers. We successfully measured the streaming potential of a biological barrier culture model with the help of our previously published versatile lab-on-a-chip device equipped with two Ag/AgCl electrodes. The inclusion of these “zeta electrodes”, a voltage preamplifier and an oscilloscope in our set-up made it possible to successfully record signals describing the surface charge properties of brain endothelial cell monolayers, used as a barrier model in our experiments. Data obtained on the new chip device were verified by comparing streaming potential results measured in the LOC device and zeta potential results by the commonly used laser-Doppler velocimetry (LDv) method and model simulations. Changes in the negative surface charge of the barrier model by treatments with neuraminidase enzyme modifying the cell membrane glycocalyx or lidocaine altering the lipid membrane charge could be measured by both the upgraded LOC device and LDv. The new chip device can help to gain meaningful new information on how surface charge is linked to barrier function in both physiological and pathological conditions.
Pose estimation is a fundamental building block of various vision applications, e.g. visual odometry, image-based localization and navigation, fusion, and augmented reality. Herein, we are interested in absolute pose estimation, which consists in determining the position and orientation of a camera with respect to a 3D world coordinate frame.
Modern applications, especially in vision-based localization and navigation for robotics and autonomous vehicles, it is often desirable to use multi-camera systems which covers large field of views. Not only classical image-based techniques, such as Structure from Motion (SfM) provide 3D measurements of a scene, but modern range sensors (e.g. Lidar, Kinect) record 3D structure directly. Thus the availability of 3D data is also becoming widespread, hence methods to estimate absolute pose of a set of cameras based on 2D measurements of the 3D scene received more attention.
Since modern cameras are frequently equipped with various location and orientation sensors, we assume that the vertical direction of the camera system (e.g. a gravity vector) is available.
In this work, we will discuss the problem of absolute pose estimation in case of a generalized camera using straight lines, which are common in urban environment. The only assumption about the imaging model is that 3D straight lines are projected via projection planes determined by the line and camera projection directions, i.e. correspondences are given as a 3D world line and its projection plane. Therefore we formulate the problem in terms of 4 unknowns using 3D line – projection plane correspondences which yields a closed form solution.
As an important special case, we address the problem of estimating the absolute pose of a multiview calibrated perspective camera system from 3D - 2D line correspondences. Herein, we propose two solutions: the first solution consists of a single linear system of equations, while the second solution yields a polynomial equation of degree three in one variable and one systems of linear equations which can be efficiently solved in closed- form.
The proposed algorithms have been evaluated on various synthetic datasets as well as on real data. All of the solutions can be used as a minimal solver as well as a least squares solver without reformulation. Experimental results confirm state of the art performance both in terms of quality and computing time.
Keywords: absolute pose estimation, vertical direction, line correspondences, generalized camera, multiview camera system
In this paper, we address the problem of estimating the absolute pose of a multiview calibrated perspective camera system from 3D - 2D line correspondences. We assume, that the vertical direction is known, which is often the case when the camera system is coupled with an IMU sensor, but it can also be obtained from vanishing points constructed in the images. Herein, we propose two solutions, both can be used as a minimal solver as well as a least squares solver without reformulation. The first solution consists of a single linear system of equations, while the second solution yields a polynomial equation of degree three in one variable and one systems of linear equations which can be efficiently solved in closed-form. The proposed algorithms have been evaluated on various synthetic datasets as well as on real data. Experimental results confirm state of the art performance both in terms of quality and computing time.
We propose a novel method to compute the absolute pose of a generalized camera based on straight lines, which are common in urban environment. The only assumption about the imaging model is that 3D straight lines are projected via projection planes determined by the line and camera projection directions, i.e. correspondences are given as a 3D world line and its projection plane. Since modern cameras are frequently equipped with various location and orientation sensors, we assume that the vertical direction (e.g. a gravity vector) is available. Therefore we formulate the problem in terms of 4 unknowns using 3D line - projection plane correspondences which yields a closed form solution. The solution can be used as a minimal solver as well as a least squares solver without reformulation. The proposed algorithm have been evaluated on various synthetic datasets as well as on real data. Experimental results confirm state of the art performance both in terms of quality and computing time.


